Technology forecasting is a systematic process used to predict the future development, adoption and impact of technologies. Various methods and techniques are employed to anticipate technological trends, thereby helping organizations make informed decisions and plan for the future.
![]()
A technology roadmap helps teams document the rationale for when, why, how, and what technology solutions can help the business move forward.
From a practical perspective, the roadmap should also outline what types of tools are best to spend money on and the most effective way to introduce new systems and processes.
The roadmap can also help you connect the technology the company needs with its long- and short-term business goals at a strategic level.
A technology roadmap typically includes:
Company or team goals
New system capabilities
Release plans for each tool
The steps to achieve
The necessary resources
The necessary training
Potential risk factors or barriers to consider
Status Report Reviews
Multiple teams and stakeholders are typically involved in the technology roadmap, from IT to general managers, product, project, operations, engineering, finance, sales, marketing and legal aspects.
The roadmap helps everyone align and understand how different implementation tasks and responsibilities impact their productivity.
Cross-impact analysis is the general name given to a family of techniques designed to assess changes in the probability of occurrence of a given set of events following the actual occurrence of one of them . The cross-impact model was introduced as a way to account for interactions between a set of forecasts, when these interactions may not have been considered when developing individual forecasts.
Cross-impact analysis is primarily used in foresight and technology forecasting studies rather than in foresight exercises per se. In the past this tool was used as a simulation method and in combination with the Delphi method.
The steps described in this section are valid for different variations of the cross-impact analysis. The steps necessary for implementing the SMIC method (developed in France in 1974 by Duperrin and Godet), which is based on dedicated software, are described here.
The list of events to study can also be established with the support of experts on the selected issue, or can come from other methods used to gather opinions, such as the Delphi method.
Design of the probability scale and definition of the time horizon: The definition of a probability scale is necessary to translate experts' qualitative assessment of the degree of occurrence (e.g. most likely, most likely, etc.) into probabilities. In general, the probability scale for cross-impact methods typically ranges from 0 (impossible event) to 1 (almost certain event).
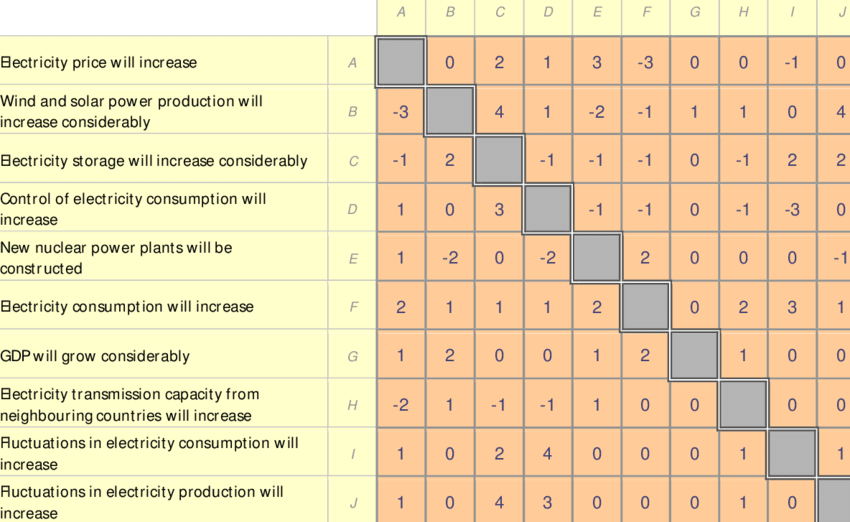
Estimation of probabilities: in this step, the initial probability of occurrence of each event is estimated. Next, the conditional probabilities in a cross-impact matrix are estimated in response to the following question: "If event x occurs, what is the new probability of event j occurring?" The entire cross-impact matrix is completed by asking this question for each combination of occurrence event and impacted event. The aim of the SMIC is to enable the consistency of expert estimates to be verified. The SMIC method invites experts to answer a grid to the following questions:
• the probability of occurrence of each unique event at a given time horizon
• the conditional probabilities of the separate event taken in pairs at a given time horizon:
• P (i/j) probability of i if j occurs
• P (i /not j) probability of i if j does not occur
Generation of scenarios: THE result of the application of a cross-impact model is a production of scenarios.
Regardless of how the question of probability assignment is resolved in specific cross-impact models, the usual procedure is to perform a Monte Carlo simulation (Martino and Chen, 1978). Each run of the model produces a synthetic future history, or scenario, that includes the occurrence of certain events and the non-occurrence of others.
The model is therefore run enough times (around 100 in the SMIC version) so that all of the output scenarios represent a statistically valid sample of the possible scenarios that the model could produce.
In a model with n events, possible scenarios “2 to the power of n” are generated, each different from all the others by the occurrence of at least one event. For example, if there are 10 events to consider, there are 1024 possible scenarios to estimate.
Once the cross impact matrices have been calculated, it is possible to carry out a sensitivity analysis. Sensitivity analysis involves selecting an initial probability estimate or a conditional probability estimate, over which uncertainty exists. This judgment is modified and the matrix is re-executed. If significant differences appear between this analysis and the original one, then it appears that the modified judgment plays an important role. It might be worth reconsidering this particular judgment.
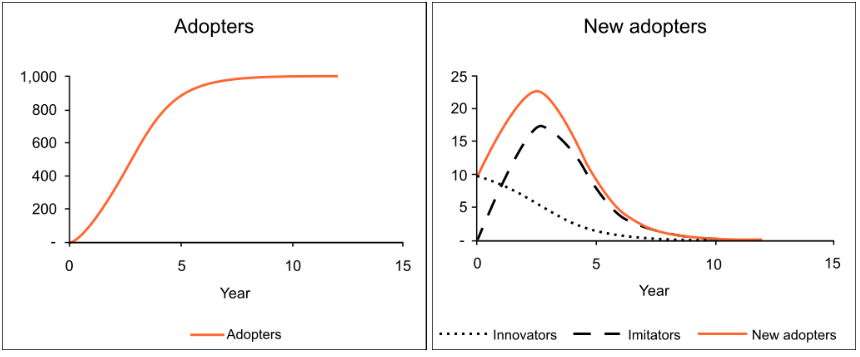
The Bass model or Bass diffusion model was developed by Frank Bass. It is a simple differential equation that describes the process by which new products are adopted by a population. The model presents a rationale for how current adopters and potential adopters of a new product interact. The basic principle of the model is that adopters can be classified as innovators or imitators, and that the speed and timing of adoption depends on their degree of innovation and the degree of imitation among adopters.
The Bass model has been widely used in forecasting, especially in new product sales forecasting and technology forecasting. Mathematically, the basic Bass diffusion is a Riccati equation with constant coefficients equivalent to the Verhulst-Pearl Logistic growth.
In 1969, Frank Bass published his article on a new growth model for consumer durable products. Previously, Everett Rogers published Diffusion of Innovations, a highly influential book describing the different stages of product adoption. Bass brought some mathematical ideas to the concept. While the Rogers model describes the four stages of the product life cycle (Introduction, Growth, Maturity, Decline), the Bass model focuses on the first two (Introduction and Growth). Some Bass-Model extensions present mathematical models for the last two (maturity and decline).
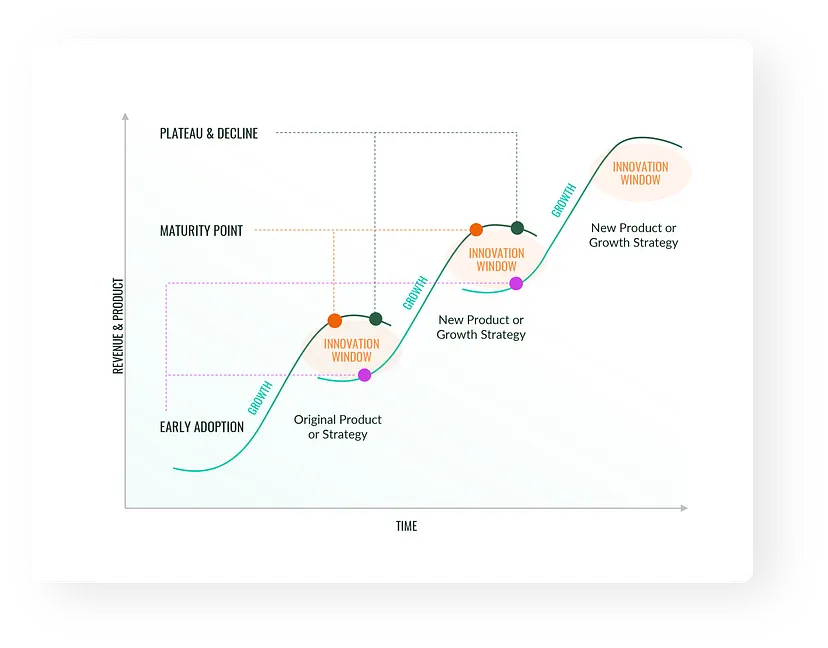
If you look at all the technological revolutions of the last few decades, you will find that they all tend to follow a similar behavior, called curve in S.
- At the beginning, technology proves expensive, bulky and poorly adopted . Improvements seem slow as fundamental concepts are understood (think of the first automobiles, for example. Development began in 1672, and it wasn't until 1769 that the first steam-powered automobile capable of transporting humans was created.).
- Then there is usually a period of rapid innovation and feature expansion, driving mass adoption (this is when engines and cars became better and cheaper, more attractive than a horse and cart and almost everyone bought one).
- Then, as the market matures, significant improvements tend to slow down and there aren't many new customers to sell to. We have reached the peak of the S-curve which is saturated.
Now a whole new technology with its own S-curve can take over . This is seen in cars (emergence of electric vehicles), planes or other inventions.