La prévision technologique est un processus systématique utilisé pour prédire le futur développement, l’adoption et l’impact des technologies. Diverses méthodes et techniques sont employées pour anticiper les tendances technologiques, aidant ainsi les organisations à prendre des décisions éclairées et à planifier pour l’avenir.
![]()
Une feuille de route technologique aide les équipes à documenter la justification de quand, pourquoi, comment et quelles solutions technologiques peuvent aider l’entreprise à aller de l’avant.
D’un point de vue pratique, la feuille de route devrait également décrire les types d’outils pour lesquels il est préférable de dépenser de l’argent et le moyen le plus efficace d’introduire de nouveaux systèmes et processus.
La feuille de route peut également vous aider à connecter la technologie dont l’entreprise a besoin avec ses objectifs commerciaux à long et à court terme à un niveau stratégique.
Une feuille de route technologique comprend généralement :
Les objectifs de l’entreprise ou d’équipe
Les nouvelles capacités du système
Les plans de publication pour chaque outil
Les étapes à atteindre
Les ressources nécessaires
La formation nécessaire
Les facteurs de risque ou obstacles potentiels à considérer
Examens des rapports d’état
Plusieurs équipes et parties prenantes sont généralement impliquées dans la feuille de route technologique, de l’informatique aux responsables généraux, en passant par les équipes de produit, de projet, des opérations, de l’ingénierie, de finances, des ventes, marketing et aux aspects juridiques.
La feuille de route permet à chacun de s’aligner et de comprendre comment les différentes tâches et responsabilités liées à la mise en œuvre impactent leur productivité.
L’analyse d’impact croisé est le nom général donné à une famille de techniques conçues pour évaluer les changements dans la probabilité d’occurrence d’un ensemble donné d’événements consécutifs à l’occurrence réelle de l’un d’entre eux. Le modèle d’impact croisé a été introduit comme moyen de prendre en compte les interactions entre un ensemble de prévisions, lorsque ces interactions n’ont peut-être pas été prises en compte lors de l’élaboration de prévisions individuelles.
L’analyse des impacts croisés est principalement utilisée dans les études prospectives et de prévision technologique plutôt que dans les exercices de prospective en soi. Dans le passé, cet outil était utilisé comme méthode de simulation et en combinaison avec la méthode Delphi.
Les étapes décrites dans cette section sont valables pour différentes variantes de l’analyse d’impact croisé. Les étapes nécessaires à la mise en œuvre de la méthode SMIC (développée en France en 1974 par Duperrin et Godet) qui s’appuie sur un logiciel dédié, sont décrites ici.
La liste des événements à étudier peut également être établie avec le soutien d’experts sur la question sélectionnée, ou peut provenir d’autres méthodes utilisées pour recueillir des avis, comme la méthode Delphi.
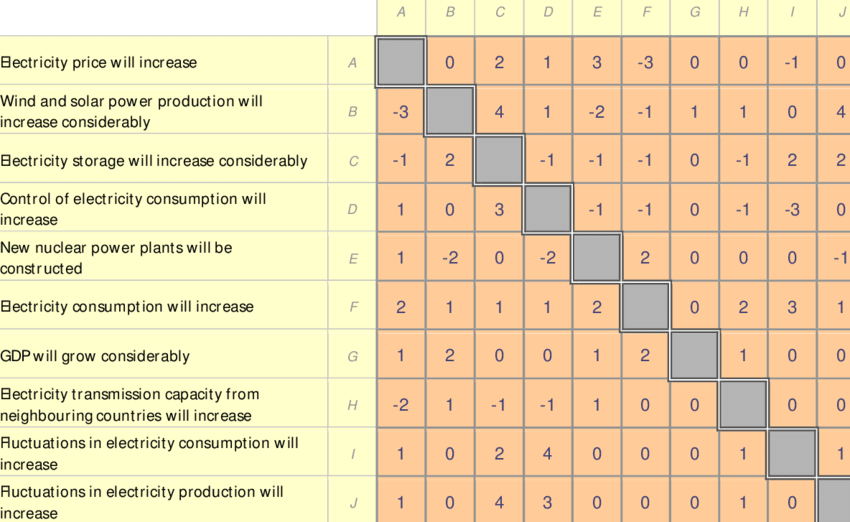
Conception de l’échelle de probabilité et définition de l’horizon temporel : La définition d’une échelle de probabilité est nécessaire pour traduire l’appréciation qualitative des experts sur le degré d’occurrence (par exemple le plus probable, le plus probable, etc.) en probabilités. En général, l’échelle de probabilité des méthodes à impact croisé va généralement de 0 (événement impossible) à 1 (événement presque certain).
Estimation des probabilités : dans cette étape, la probabilité initiale d’occurrence de chaque événement est estimée. Ensuite, les probabilités conditionnelles dans une matrice d’impact croisé sont estimées en réponse à la question suivante : « Si l’événement x se produit, quelle est la nouvelle probabilité que l’événement j se produise ? L’ensemble de la matrice des impacts croisés est complété en posant cette question pour chaque combinaison d’événement survenu et d’événement impacté. Le SMIC a pour objectif de permettre de vérifier la cohérence des estimations des experts. La méthode SMIC invite les experts à répondre à une grille aux questions suivantes :
• la probabilité d’occurrence de chaque événement unique à un horizon temporel donné
• les probabilités conditionnelles de l’événement séparé pris par paires à un horizon temporel donné :
• P (i/j) probabilité de i si j se produit
• P (i /pas j) probabilité de i si j ne se produit pas
Génération de scénarios : Le résultat de l’application d’un modèle à impacts croisés est une production de scénarios.
Quelle que soit la manière dont la question de l’attribution des probabilités est résolue dans des modèles spécifiques à impact croisé, la procédure habituelle consiste à effectuer une simulation de Monte Carlo (Martino et Chen, 1978). Chaque exécution du modèle produit un historique futur synthétique, ou scénario, qui inclut l’occurrence de certains événements et la non-occurrence d’autres.
Le modèle est donc exécuté suffisamment de fois (soit environ 100 dans la version SMIC), pour que l’ensemble des scénarios de sortie représente un échantillon statistiquement valide des scénarios possibles que le modèle pourrait produire.
ans un modèle à n événements, des scénarios possibles « 2 à la puissance n » sont générés, chacun se différenciant de tous les autres par la survenance d’au moins un événement. Par exemple, s’il y a 10 événements à considérer, il y a 1024 scénarios possibles à estimer.
Une fois les matrices d’impacts croisés calculées, il est possible de réaliser une analyse de sensibilité. L’analyse de sensibilité consiste à sélectionner une estimation de probabilité initiale ou une estimation de probabilité conditionnelle, sur laquelle existe une incertitude. Ce jugement est modifié et la matrice est réexécutée. Si des différences significatives apparaissent entre cette analyse et celle d’origine, il apparaît alors que le jugement modifié joue un rôle important. Il serait peut-être utile de reconsidérer ce jugement particulier.
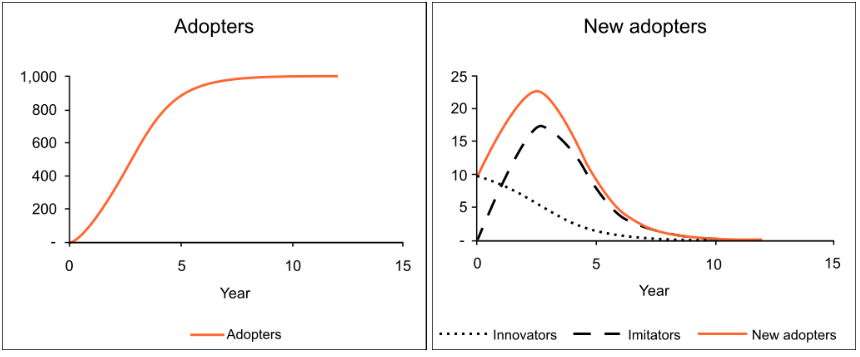
Le modèle Bass ou modèle de diffusion Bass a été développé par Frank Bass. Il s’agit d’une simple équation différentielle qui décrit le processus par lequel les nouveaux produits sont adoptés par une population. Le modèle présente une justification de la façon dont les adoptants actuels et les adoptants potentiels d’un nouveau produit interagissent. Le principe de base du modèle est que les adoptants peuvent être classés comme innovateurs ou imitateurs, et que la vitesse et le calendrier de l’adoption dépendent de leur degré d’innovation et du degré d’imitation parmi les adoptants.
Le modèle Bass a été largement utilisé dans les prévisions, en particulier dans la prévision des ventes de nouveaux produits et la prévision technologique. Mathématiquement, la diffusion de base de Bass est une équation de Riccati avec des coefficients constants équivalents à la croissance Verhulst-Pearl Logistic.
En 1969, Frank Bass a publié son article sur un nouveau modèle de croissance des produits de consommation durable. Auparavant, Everett Rogers avait publié Diffusion of Innovations, un ouvrage très influent décrivant les différentes étapes de l’adoption d’un produit. Bass a apporté quelques idées mathématiques au concept. Alors que le modèle Rogers décrit les quatre étapes du cycle de vie du produit (Introduction, Croissance, Maturité, Déclin), le modèle Bass se concentre sur les deux premières (Introduction et Croissance). Certaines extensions Bass-Model présentent des modèles mathématiques pour les deux derniers (maturité et déclin).
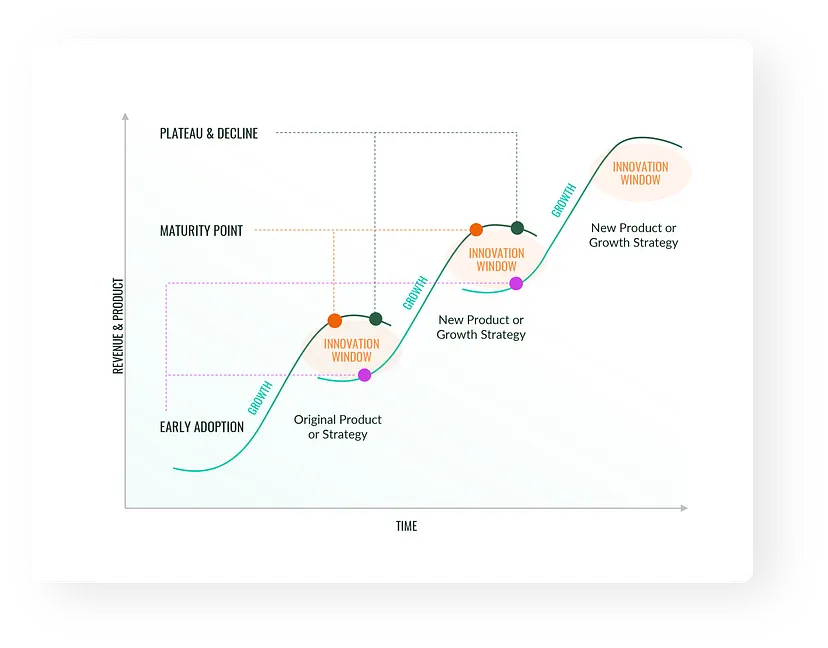
Si vous examinez toutes les révolutions technologiques des dernières décennies, vous constaterez qu’elles ont toutes tendance à suivre un comportement similaire, appelé courbe en S.
- Au début, la technologie s’avère coûteuse, encombrante et peu adoptée . Les améliorations semblent lentes à mesure que les concepts fondamentaux sont compris (pensez aux premières automobiles, par exemple. Le développement a commencé en 1672, et ce n’est qu’en 1769 que la première automobile à vapeur capable de transporter des humains a été créée.).
- Ensuite, il y a généralement une période d’innovation rapide et d’expansion des fonctionnalités, entraînant une adoption massive (c’est à ce moment-là que les moteurs et les voitures sont devenus meilleurs et moins chers, plus attrayants qu’un cheval et une charrette et que presque tout le monde en achetait un).
- Ensuite, à mesure que le marché mûrit, les améliorations significatives ont tendance à ralentir et il n’y a plus beaucoup de nouveaux clients à qui vendre. Nous avons atteint le sommet de la courbe en S qui est saturée.
Désormais, une toute nouvelle technologie avec sa propre courbe en S peut prendre le dessus . Cela se voit dans les voitures (émergence des véhicules électriques), les avions ou d’autres inventions.