The idea behind the generated knowledge approach is to ask the LLM to generate potentially useful information about a given question/prompt before generating a final answer.
![]()
The content below covers the more technical context in which the approach was introduced. It follows the model of the two intermediate steps (knowledge generation and integration) that we saw above.
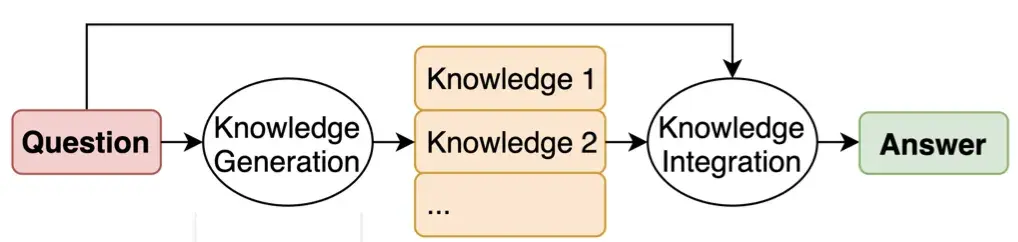
In the knowledge generation step, the LLM is prompted to generate a set of facts about the question. The LLM is prompted to respond in a few-shot prompting fashion, as shown below. M different completions are generated using this same prompt (similar to the self-consistency approach).

Then we generate questions “augmented knowledge” and encourage the LLM to get final answers. The easiest way to understand this is through an example.
Suppose we are trying to answer the question "Most kangaroos have limbs." ". Let's assume that at the knowledge generation stage, we have generated 2 pieces of knowledge (M=2):
Knowledge 1: Kangaroos are marsupials that live in Australia.
Knowledge 2: Kangaroos are marsupials that have 5 limbs.
Now we chain each knowledge with the question to generate knowledge-enhanced questions:
Augmented Knowledge Question 1: Most kangaroos have limbs. Kangaroos are marsupials that live in Australia.
Augmented Knowledge Question 2: Most kangaroos have limbs. . Kangaroos are marsupials that have 5 limbs.
We then ask the LLM these knowledge-enriched questions and obtain the final answer proposals:
Answer 1: 4
Answer 2: 5
We select the answer with the highest probability as the final answer. The highest probability can be the softmax probability of the answer token or the log probability of the answer token(s).
For example, let's say you want to write a short blog post about an animal, like Spirit Bears. Before you ask the LLM to write the blog post, you can ask it to generate some information about Spirit Bears. This will help the LLM to write a more informative blog post. There are two easy ways to do this.
The first approach asks the LLM to generate knowledge and then write the message, all with a single prompt.
Generate 4 facts about the Kermode bear, then use these facts to write a short blog post using the information:
Here is the answer:

In this approach, we first invite the LLM to generate facts about the bear:
Generate 4 facts about the Kermode bear:

Then we feed this information into another prompt to write the blog post:
1. The Kermode bear, also known as the Spirit Bear, is a rare subspecies of the American black bear found in British Columbia, Canada. 2. The Kermode bear has a unique white or cream-colored coat, which is caused by a recessive gene. 3. The Kermode bear is a symbol of hope and renewal for the First Nations people of British Columbia. 4. The Kermode bear is a protected species and is listed as a species of special concern by the Committee on the Status of Endangered Wildlife in Canada. Use the above facts to write a one paragraph blog post about the Kermode bear:

The generated knowledge approach was actually introduced for a completely different task, that of answering difficult questions. Consider the following question, which the LLM answers incorrectly:

If we first ask the LLM to generate facts about Congo and South Africa, we can then use this information to answer the question correctly. In theory, this is similar to the CoT prompt, since we are effectively asking the LLM to generate intermediate reasoning in the form of related facts.
Let's start with the first step, knowledge generation. We can ask the LLM to generate facts about Congo and South Africa:

Next, let's use this knowledge to answer the question correctly. This is the knowledge integration step:

Here is an example where knowledge generation allows us to break down the problem and therefore answer the question:

So the following prompt, the llm keeps in memory the breakdown of the problem, and will therefore check the different points cited during its response:
