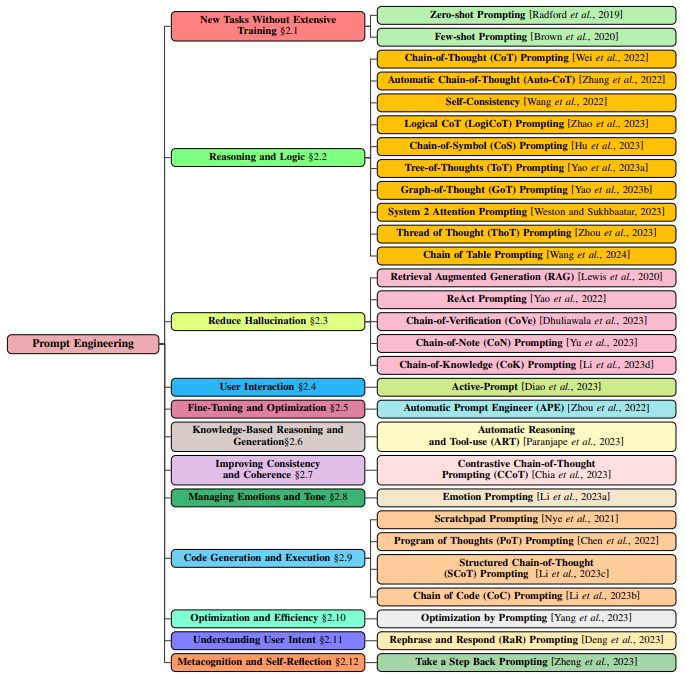
Evaluating the results of advanced incentive techniques is essential to ensure that the results generated by the model are accurate, reliable, and useful for the task at hand. Several evaluation methods can be applied depending on the nature of the task. research :
Accuracy and relevance : For factual tasks, such as synthesizing research or answering specific questions, the accuracy of the results should be checked against reliable sources. This is especially important for zero- or few-trial tasks, where the model relies heavily on pre-existing knowledge.
Logical consistency : When using the chain of thought or self-consistency prompt, it is important to assess the logical flow of the reasoning. Does the result make sense step by step? For research tasks that involve multiple-step reasoning, make sure that each step is valid and contributes to the conclusion global.
Consistency : In the self-consistency prompt, assess the consistency of multiple model results. If multiple responses converge to the same answer, this increases confidence in the accuracy of the result. If there is significant variation, it may be necessary to refine the prompt or task.
Completeness : Especially in the case of a CoT prompt, make sure that the model addresses all parts of the task. For example, if the prompt asks the model to explain both natural and human drivers of climate change, the answer should cover both aspects comprehensively.
Bias and objectivity : assess whether the model has introduced bias into its responses, especially for sensitive research topics. The model should remain objective and refrain from giving biased opinions unless the task specifically requires subjective input.
User testing : For tasks requiring complex reasoning, such as solving mathematical or scientific problems, results can be evaluated by subject matter experts or through user studies to assess their validity and usability.
By applying these evaluation methods, users can ensure that advanced prompting techniques produce reliable and high-quality results for various research tasks.
Optimizing prompt performance in large language models (LLMs) like GPT-4 is critical to ensuring that answers are accurate, relevant, and consistent with user expectations. By adjusting how the model interprets inputs and generates outputs, users can exercise greater control over the quality of answers. Two key strategies for optimizing prompt performance include: temperature And sampling and the use of contextual information.
Temperature : This parameter controls the randomness of the model output. The scale typically ranges from 0 to 1.
Lower temperatures (closer to 0) produce more targeted and deterministic outputs. The model is more likely to choose the most likely next word, leading to accurate and consistent answers. This is ideal for factual, technical, or formal writing where accuracy and clarity are essential.
Higher temperatures (closer to 1) introduce more diversity and randomness into the output. The model is less constrained by probability, which encourages creativity and variability in responses. This setting works well for creative tasks, such as story generation, brainstorming, or open-ended questions.
Example :
Prompt: “Write a formal explanation of quantum mechanics.”
With temperature set to 0.2, the model will provide a clear and accurate explanation based on high probability tokens.
With a temperature of 0.8, the response may include more varied, potentially creative or unconventional explanations that could be useful for exploring different perspectives.
Top-p (kernel) sampling: In Top-p sampling, the model selects the highest percentage of likely next words rather than strictly following the highest probability path. The model continues sampling until the cumulative probability reaches a user-defined threshold (p).
Lower values of p (e.g., 0.5) lead to more conservative responses, while higher values (e.g., 0.9) introduce more variety into the output.
Example :
Prompt: “Describe potential future applications of artificial intelligence in healthcare.”
At a higher p-value of 0.5, the model will provide standard and highly probable responses, such as improvements in diagnostic tools and personalized treatments.
With a higher p-value of 0.9, the model will include more diverse and possibly speculative responses, such as AI advances in emotional support for patients or new applications in telemedicine.
In many cases, the performance of a prompt can be significantly improved by integrating a context additional input. This technique guides the model more effectively by providing it with relevant background information or framing the prompt in a specific way that leads to more targeted and accurate results.
Contextual prompts are designed to include external data, background knowledge, or specific instructions that help guide the model toward a more specific answer. For example, instead of asking a general question like “How important is renewable energy?”, incorporating context into the prompt, such as a geographic focus or a specific time period, can lead to more targeted and relevant answers.
Example :
Prompt: “According to the IPCC 2022 report, explain how renewable energy contributes to reducing carbon emissions in developing countries.”
The inclusion of the IPCC report in the prompt restricts the scope of the model, causing it to rely on specific knowledge about carbon emissions and renewable energy trends in developing countries.
By incorporating such contextual clues, users can tailor responses to their specific needs, making the model more responsive to complex or specialized requests.
Another effective strategy is to assign roles to the model, in combination with built-in context. For example, asking ChatGPT to “act as a climate scientist” when answering a question about renewable energy ensures that the result is framed with the appropriate expertise and guidance.
Example :
Prompt: “As a climate scientist, explain the long-term environmental benefits of wind energy in Europe, focusing on the last decade.”
The role-based prompt gives the model clear guidance on the expertise expected in the response, while the built-in context focuses it on a specific geographic area and time period.